

NVIDIA RTX PRO 6000 Blackwell AI GPU Server Successfully Tested at menkiSys with CUDA 13, SGLang and Qwen
NVIDIA RTX PRO 6000 Blackwell AI GPU Server Successfully Tested at menkiSys
menkiSys is expanding its AI GPU infrastructure and is currently testing a new high-end platform based on two NVIDIA RTX PRO 6000 Blackwell GPUs, each with 96 GB vRAM. This provides a total of 192 GB GPU memory in this system for modern AI workloads, Large Language Models, inference, vision-language models, GPU computing and professional AI applications.
The server is based on a powerful AMD EPYC platform with 64 CPU cores, 512 GB RAM and two NVIDIA RTX PRO 6000 Blackwell GPUs. The total hardware value, including the server system, exceeds EUR 60,000. With this setup, menkiSys operates an exclusive AI infrastructure that is particularly attractive for demanding companies, developers, IT service providers, research institutions and professional AI projects.
The new NVIDIA driver was successfully used in the current test environment:
NVIDIA Driver Version: 580.126.08
CUDA Version: 13
What is particularly relevant is that the production-oriented test with SGLang, CUDA 13, FlashInfer and the Qwen2.5-VL-32B model was successfully launched. While other configurations were not successful during testing, the CUDA 13 variant with the matching SGLang container worked reliably. This clearly shows how important current drivers, suitable container images, NVIDIA Runtime, CUDA versions and correctly tuned inference parameters are in the field of modern AI infrastructure.
Among other things, the following technical stack was tested:
docker run -d --name qwen-sglang-cu13 \
- --runtime=nvidia \
- --device nvidia.com/gpu=all \
- --ipc=host \
- --ulimit memlock=-1 \
- --ulimit stack=67108864 \
- --shm-size=64g \
- -p 30320:8000 \
- -v /opt/llm-models/qwen2.5-vl-32b:/opt/llm-models/qwen2.5-vl-32b:ro \
- lmsysorg/sglang:dev-cu13 \
- python3 -m sglang.launch_server \
- --model-path /opt/llm-models/qwen2.5-vl-32b \
- --host 0.0.0.0 \
- --port 8000 \
- --mem-fraction-static 0.92 \
- --max-running-requests 128 \
- --max-total-tokens 114688 \
- --chunked-prefill-size 16384 \
- --max-prefill-tokens 32768 \
- --schedule-policy lpm \
- --attention-backend flashinfer \
- --sampling-backend flashinfer \
- --cuda-graph-bs 1 2 4 8 16 32 48 64 \
- --log-level info
This test represents an important technical milestone for menkiSys. It demonstrates that current AI models and modern inference engines can be operated on a professional NVIDIA Blackwell platform inside the menkiSys data center. The platform is suitable for LLM inference, private AI assistants, chatbots, API-based AI services, RAG systems, document analysis, image analysis, vision-language models, AI agents, AI-assisted software development, machine learning, rendering and other GPU-intensive workloads.
This infrastructure is especially interesting for companies that want to operate models such as Qwen, Llama, Mistral, Mixtral, DeepSeek, Gemma or other open-source LLMs. In combination with technologies such as Open WebUI, SGLang, vLLM, Ollama, LiteLLM Proxy, Docker, NVIDIA Container Runtime, CUDA 13 and FlashInfer, powerful AI platforms for internal and external business applications can be implemented.
With this development, menkiSys is not only providing classic server and hosting infrastructure, but is actively building modern solutions for AI GPU hosting, LLM hosting, AI API deployment, private AI platforms and GDPR-compliant AI infrastructure from Austria.
A major advantage for companies is that they do not need to make their own investment in expensive GPU hardware, cooling, power supply, driver maintenance, server operation and data center infrastructure. Instead, customers can access professional NVIDIA GPU servers in the menkiSys data center and run their AI projects on a stable, powerful and controlled platform.
A current screenshot from the test system shows the NVIDIA RTX PRO 6000 Blackwell GPUs in operation:
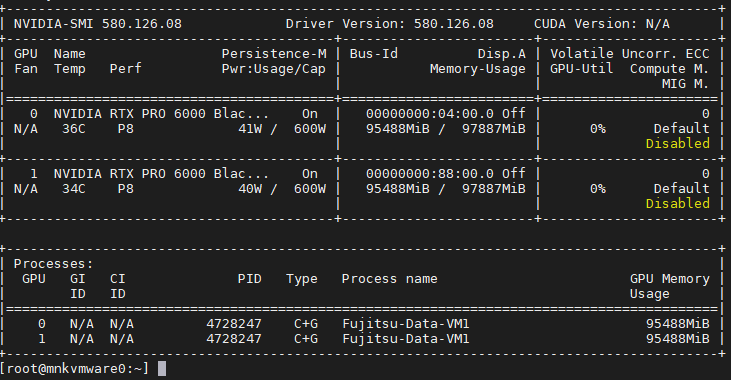
NVIDIA RTX PRO 6000 Blackwell GPU Server with NVIDIA Driver 580.126.08 and CUDA 13 at menkiSys
A video from the current test environment is also available:
https://meinecloud.menkisys.at/index.php/s/c73C4JJWH936AEX
With this platform, menkiSys positions itself as an Austrian provider of professional AI GPU servers, NVIDIA Blackwell hosting, LLM infrastructure and enterprise AI workloads. Companies, developers and IT service providers gain access to exclusive high-end GPU performance without having to purchase and operate hardware worth more than EUR 60,000 themselves.
Companies that want to operate their own AI models, Open WebUI, Qwen, Llama, Mistral, SGLang, vLLM, Ollama, LiteLLM or an OpenAI-compatible API on powerful GPU infrastructure can contact menkiSys directly.
Relevant topics:
NVIDIA RTX PRO 6000 Blackwell, NVIDIA Blackwell GPU Server, CUDA 13, NVIDIA Driver 580.126.08, AI GPU Server Austria, rent GPU server, rent vGPU server, LLM hosting, Qwen hosting, Llama server, Mistral server, Open WebUI hosting, SGLang server, vLLM hosting, Ollama server, LiteLLM Proxy, AI API hosting, Private AI Cloud, GDPR-compliant AI infrastructure, enterprise AI hosting, GPU inference server and dedicated NVIDIA GPU servers by menkiSys.
« Back
